NgeNet论文理解
由于点云传统配准(ICP:迭代最近点算法)效果不佳,于是考虑使用深度学习的方法。 这里采用NgeNet。
Neighborhood-aware Geometric Encoding Network 邻域感知几何编码网络
Introduction
点云配准深度学习方法的分类
作者将其分为了两种
- end-to-end:将feature learning 和 transformation estimation 融合到了一个模型
- 其中有一些方法依赖相关性的建立来进行后续的Procrustes分析
- 而其他方法则更关注点云之间的全局特征
- feature-learning:更加关注learning of discriminative point feature(学习辨别性的点的特征),而transformation则是由pose estimators来估计的
提出网络
NgeNet利用多尺度结构明确地生成具有多种邻域大小的点状特征,并利用几何指导的编码模块来最大限度地利用几何信息。具体来说,设计了一个投票机制,为每个点选择一个合适的邻域大小,并拒绝在无法区分的表面上出现虚假的特征。
主要贡献
- 多尺度结构与几何引导编码相结合,产生多层次的几何和语义信息编码的特征。
- 多层次的一致性投票,为每个点选择适当的邻域并拒绝虚假的邻域。
- 我们的方法中所提出的技术是与模型无关的,能够很容易地移植到其他骨干结构上并提高性能。
Preliminaries (引言)
点云配准问题的数学表达
arg 是变元(即自变量argument)的英文缩写。 arg min 就是使后面这个式子达到最小值时的变量的取值 arg max 就是使后面这个式子达到最大值时的变量的取值 例如 函数F(x,y): arg min F(x,y)就是指当F(x,y)取得最小值时,变量x,y的取值 arg max F(x,y)就是指当F(x,y)取得最大值时,变量x,y的取值
\[ arg\ \underset{T}{\mathrm{min}}\frac{1}{|\sigma|}\sum_{(i, j)\in \sigma}||T (x_i ) − y_j ||_2 \]
Cardinal Number(基数):集合论中刻画集合大小的数
邻域分析
在特征学习中常常用到encoder-decoder网络来提取特征; 模型的输入为\(X\in\mathbb{R}^3\) 维数从\(N\times 3\) -> $N C $意思是每个点输出C维的特征
有两种方式去影响领域的范围一个是依靠连续的卷积层,隐形的增加了领域的范围;另一个是在encoder-decoder网络中常常使用两倍大小的分层卷积层来模拟点云的down sample。
方法
网络
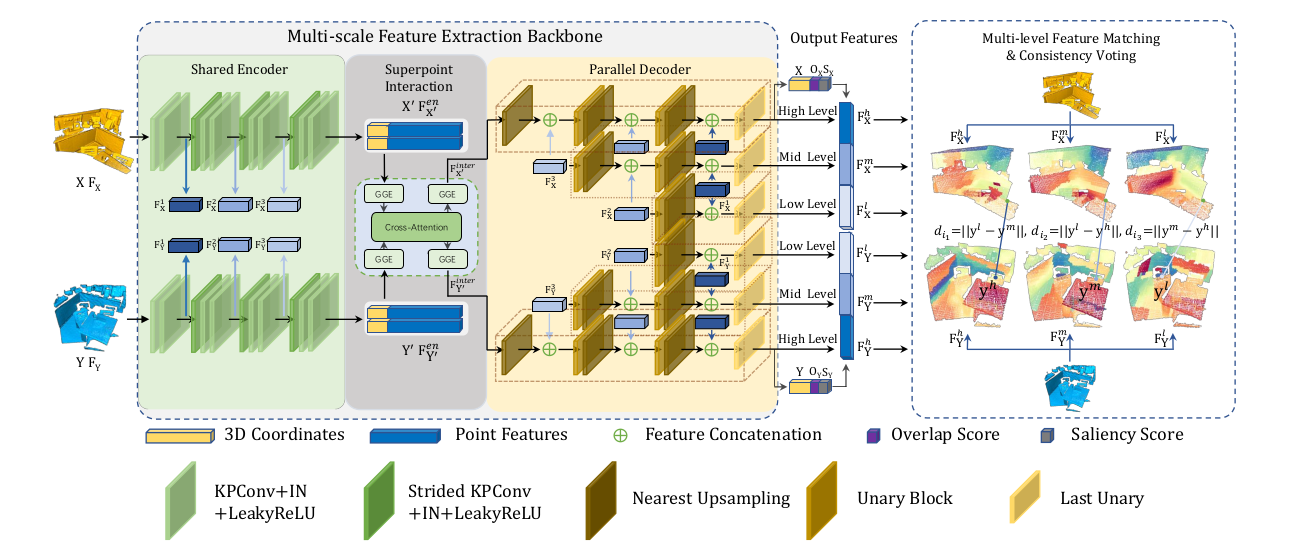
可以很清楚的看到NgeNet是一个encoder-decoder网络 - encoder模块由:residual-style KPConv/strided KPConv层、instance norm层和Leaky ReLU层(k=0.1)组成
KPConv 是用于三维点云中的一种卷积方式
- decoder模块由:decoder中的上采样块采用最近搜索来进行特征插值。 unary block由一个线性(MLP)层、一个实例范数层和一个 Leaky ReLU 层 (k=0.1) 组成,而last unary block仅由一个线性层(MLP)组成
Input是什么?
Input为the source point cloud \(X\) and its initial descriptor \(F_X\) , the target point cloud \(Y\) and its initial descriptor \(F_Y\)
- 其中\(F_X\) and \(F_Y\) 都被init为全部为\(1\)的矩阵
组成部分
SIAMESE MULTI - SCALE BACKBONE
连体式多级骨干(什么鬼翻译
用途:用于处理输入的点云
如何工作?
Shared Encoder:可以在绿色的Encoder部分看到一共做了四次卷积;这样做是为了拓展领域特征。此时一共有四个输出,最后的输出得到Super points \(X'\) (\(X'\)集合会在下文经常提到其中包括他的点\(x'_i \in X '\))和它的feature \(F^{en}_{X'}\)(我理解上标的en意思是end;最后一个输出);前三步输出的feature作为中间变量也被保存了下来,为了decoder去生成multi-scale的feature。这三个中间变量被记为\(F^1_{X}, F^2_{X}, F^3_{X}\)。这里需要注意的是,每个点特征的邻接点的感知范围从\(F^1_X\)延伸到\(F^3_{X}\) (最后一句话是KPConv的知识)
- 最后Shared Encoder输出的是\(X' \in \mathbb{R}^{N' \times 3}\) 和\(F^{en}_{X'} \in \mathbb{R}^{N' \times D_{en} }\) ,加起来是应该是\((X', F^{en}_{X'}) \in \mathbb{R}^{N' \times (3+D_en)}\)(有待考证)
Parallel Decoder:上面说在decoder的时候需要用到我们刚才保存的\(F^1_{X}, F^2_{X}, F^3_{X}\),同时还有之后会介绍的\(F^{inter}_{X'}\),一共这四个输入。最后得到的output是关于\(X'\)的高、中、低级别的feature
现在我们定义一个函数(后面要用) \[ \phi (F^1 , F^2 , g) = cat[Up(g(F^2 )), F^1 ] \] 其中\(F^1\)和\(F^2\)是输入的feature,\(g\)是一个代表MLP或者Identity Layer的函数, \(cat\)表示concatenation(拼接矩阵),\(Up\)是nearest upsampling
现在可以表示 \(F^l_X , F^m_X\) 和 \(F^h_X\) 的计算方式
\[ \begin{split} F^l_X &= MLP_2(\phi(F^1_X, F^2_X, MLP_1), \\ F^m_X &= MLP_5(\phi(F^1_X, \phi (F^2_X, F^3_X, MLP_3), MLP_4), \\ F^h_X &= MLP_8(\phi(F^1_X, \phi (F^2_X, \phi (F^3_X, F^{inter}_X, Identity), MLP_6), MLP_7 ). \end{split} \]
- 同时给出overlap(重复性)分数\(O_X\)和saliency(显著性)分数\(S_X\)
GEOMETRIC - GUIDED ENCODING
几何学引导式编码
GGE模块是一个 一个输入一个输出的模块
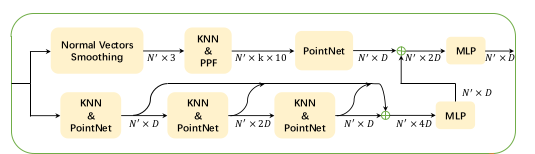
用途:GGE将super points和潜在的feature(也就是Shared Encoder输出的\((X', F^{en}_{X'}) \in \mathbb{R}^{N' \times (3 + D_{en})}\))作为输入;然后输出几何增强后的feature
如何工作?
- Normal vectors smoothing:这里计算Normal vector的方式比较特别。这一步的目的是去获得super points的Normal vector,但是他没有直接去用open3d的库直接计算。而是将super points的点映射回原来的全部点集中。再通过全部点集中,super points周围点的normal vectors去平均得到super points的normal vector。
\[ N_{X_i^{'}}=\frac{1}{|J_i^N|}\sum_{x_j \in J_i^N}{N_{X_j}} \]
公式里面\(J_i^N = \{x_j| \left|| x_j-x'_i \right|| < r^N \}\) 其中\(x_j\in X\),\(r^N\)是\(x'_i\)的邻域。
稍微解释一下公式:
\(N_{X'_i}\)是我们想要的\(X'\)的normal vector的集合
\(J^N_i\)代表得是点\(x_i\)邻域内的点
- Geometric encoding:这里我们想要的是每个点的几何特征,记为\(G_{x'_i}\),利用PPF(Point Pair feature)去计算几何特征
\[ \begin{equation} \begin{split} PPF(x'_i, x'_j) &= (\angle(x'_j-x'_i, N_{x'_i}), \angle(x'_j-x'_i, N_{x'_j}), \angle(N_{x'_i}, N_{x'_j}), \left|| x'_i - x'_j\right||_2), \\ G_{x'_j} &= f_1(x'_i, x'_j-x'_i, PPF(x'_i, x'_j)), \\ G_{x'_i} &= max\{ G_{x'_j}|x'_j \in J^G_i \}. \end{split} \end{equation} \]
公式里面\(\angle(\cdot, \cdot)\in(0, \pi)\) 代表两个向量之间的夹角, \(f_1\)是pointnet里的一个函数, \(J^G_i = \{x'_j \left|| x'_j-x'_i\right||<r^G\}\),\(r^G\)是\(x'_i\)邻域的半径,\(max(\cdot)\)意思是channel-wise max-pooling
这个公式也解释一下:
PPF我这里理解的就是一个四维向量包含了(按照NgeNet的顺序),一个法向量和{两个法向量之间的向量d}的夹角,另一个法向量和{两个法向量之间的向量d}的夹角,两个法向量的夹角,两点之间的距离。对应下图的\((F_2, F_3, F_4, F_1)\)
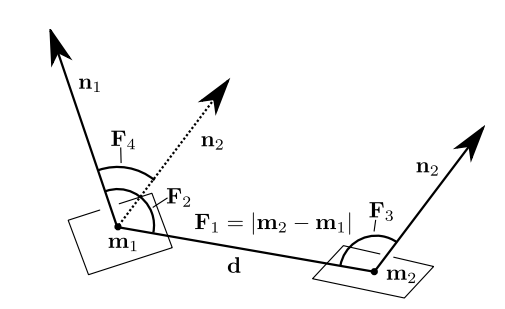
\(f_1\)函数:暂时不清楚什么意思 \(G_{x'_i}\):找到\(G_{x'_j}\)中最大的;至于channel-wise再点云中代表什么几何含义,暂时不清楚
- Semantic encoding:需要更新
损失函数
这里我们将损失函数从两个方面来看:特征损失 和 重叠与显着性损失
特征损失
这里说的特征损失,就是我们之前提到的\(F^h_X, F^m_X, F^l_X, F^h_Y, F^m_Y, F^l_Y\) 两个点云三个类别的特征。
重叠与显着性损失
投票机制
为什么要投票
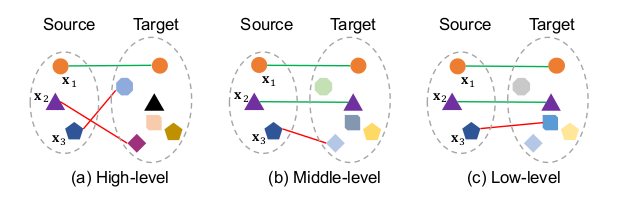
在Parallel Decoder我们强调了,在每一次计算特征的时候,我们都保存下来了那些中间变量;他们是\(F^l_X\) 和\(F^m_X\) ,最后的输出是\(F^h_X\) 。
此时它们三个分别可以决定哪些source的特征点和target的特征点可以一一对应。那么每一个特征点都会存在三种方案。所以需要通过投票决定使用哪一种。
如何投票
